3. Applying HMP to real data#
For this tutorial we will use the data from application 2 of this this paper. For the purpose of this tutorial we will only use the first 5 participants of the data (see the HMP paper for the method and GWeindel/man_hmp for the whole (preprocessed) data).
In this experiment, participants performed a random-dot motion task. They were asked to indicate the direction of motion of a cloud of moving dots. While a proportion of the dots moved in a target direction, the remainder moved randomly and makes the direction discrimination more difficult. Difficulty of the task was calibrated per subject. Prior to each trial, participants received a cue that indicated whether they should respond as quickly as possible or whether they should focus on giving an accurate response: the ‘speed’ and ‘accuracy’ conditions. In this tutorial we will ignore the difference between these conditions, but in the next tutorial we will look at how we can take conditions into account in the HMP analysis.
Data preparation#
First, we load the required packages and download the data. Depending on your internet connection this can take some time
[1]:
import os
import matplotlib.pyplot as plt
import requests
from mne.io import read_info
import hmp
# Declaring path where the EEG data will be stored
epoch_data_path = os.path.join('sample_data', 'eeg')
os.makedirs(epoch_data_path, exist_ok=True)
# URLs of the first 5 participants in the SAT experiment, navigate the osf folder and adapt those if you want to do this tutorial on other data (e.g. P3, N2pc)
base = "https://files.osf.io/v1/resources/29tgr/providers/github/results/replication/SAT_data/"
file_urls = [base + f"processed_500Hz_{(x+1):04d}_epo.fif" for x in range(5)]
# Download and save each file if not already in folder
for i, url in enumerate(file_urls, start=1):
file_path = os.path.join(epoch_data_path, f'participant{i}_epo.fif')
if not os.path.exists(file_path):
response = requests.get(url)
with open(file_path, 'wb') as f:
f.write(response.content)
# Recovering individual files and participant names
subj_files = [os.path.join(epoch_data_path, f) for f in os.listdir(epoch_data_path) if f.endswith('.fif')] # Create a list of files with full paths
subj_names = [os.path.splitext(f)[0] for f in os.listdir(epoch_data_path) if f.endswith('.fif')] # Extract subject names based on file names
# Recovering channel information (assuming the same for all participant)
info = read_info(subj_files[0], verbose=False)
[2]:
# At what frequency we want the data, high sampling frequencies require a lot of RAM, decrease when necessary
sfreq = 300
# Then we read the data as shown in Tutorial 1
epoch_data = hmp.io.read_mne_data(subj_files, data_format='epochs', sfreq=sfreq,
verbose=False, subj_name=subj_names)#Turning verbose off for the documentation but it is recommended to leave it on as some output from MNE might be useful
print(epoch_data)
Processing participant sample_data/eeg/participant3_epo.fif's epochs eeg
Processing participant sample_data/eeg/participant4_epo.fif's epochs eeg
Processing participant sample_data/eeg/participant5_epo.fif's epochs eeg
Processing participant sample_data/eeg/participant1_epo.fif's epochs eeg
Processing participant sample_data/eeg/participant2_epo.fif's epochs eeg
<xarray.Dataset> Size: 115MB
Dimensions: (participant: 5, epoch: 200, channel: 30, sample: 960)
Coordinates:
* epoch (epoch) int64 2kB 0 1 2 3 4 5 6 ... 193 194 195 196 197 198 199
* channel (channel) <U3 360B 'Fp1' 'Fp2' 'AFz' 'F7' ... 'CPz' 'CP2' 'CP6'
* sample (sample) int64 8kB -60 -59 -58 -57 -56 ... 895 896 897 898 899
stim (participant, epoch) float64 8kB 1.0 nan 1.0 ... 2.0 1.0 2.0
resp (participant, epoch) object 8kB 'resp_left' ... 'resp_right'
RT (participant, epoch) float64 8kB 907.0 nan ... 468.0 350.0
cue (participant, epoch) object 8kB 'AC' nan 'AC' ... 'SP' 'AC'
movement (participant, epoch) object 8kB 'stim_left' ... 'stim_right'
trigger (participant, epoch) object 8kB 'AC/stim_left/resp_left' ......
* participant (participant) <U16 320B 'participant3_epo' ... 'participant2...
Data variables:
data (participant, epoch, channel, sample) float32 115MB 1.437 .....
Attributes:
sfreq: 300.0
lowpass: 35.0
highpass: 1.0
reference: None
n_trials: 920
tmin: -0.2
tmax: 2.9966666666666666
As you can see the HMP formatted EEG dataset contains some info on the experiment such as the sampling frequency, the number of trials, the number of participants, and the number of channels. The data is epoched between stimulus and response onset (RT) and it also contains metadata such as the RTs and other information on the experiment.
At this point we have the epoched EEG data with 30 channels, which we need to transform to PC space.
[3]:
preprocessed = hmp.transformers.ProjPCA(epoch_data, interval_id = "RT", n_comp=10)
900 positively defined intervalsbetween 0.0033333333333333335 and inf seconds.
Rejection summary:
0 trials rejected based on threshold of None
19 trials rejected based on interval limit of (0.0033333333333333335, inf)
1 trials detected with no interval (e.g. preprocessing or interval exceeding epoch))
/home/gabriel/ownCloud/projects/RUGUU/hmp/hmp/transformers/base.py:135: UserWarning: Found intervals with a max value value of 2172.0, assuming intervals are in milliseconds and converting to seconds
warn(f"Found intervals with a max value value of {np.round(max_rt,2)}"
The selection of principal components is used for computational reasons, higher number of PCs give more accurate solution but also increases RAM usage. The advice is thus to have the largest amount of PCs that fits in your computer. Here for the example and speed reason we use 10 PCs as declared in n_comp. Note that lower than 10 PCs is usually not recommended as you’ll be wasting information that can be used by HMP.
After this operation the data is now arranged as 10 PCs x 64690 samples: all trials of all participants were concatenated for the remainder of the analysis.
[4]:
preprocessed.data
[4]:
<xarray.DataArray (sample: 654, component: 10, trial: 900)> Size: 24MB
array([[[ 1.5310520e-01, 2.6818237e-01, 5.2298021e-02, ...,
7.9390293e-01, 9.6655685e-01, -5.5403852e-01],
[-1.2010367e+00, 1.1731410e+00, 7.1406670e-02, ...,
-7.4618518e-01, -1.8281198e-01, 3.8645348e-01],
[-3.0051148e-01, -3.6731592e-01, -8.8190877e-01, ...,
1.3288690e-01, -4.6341172e-01, -9.4244581e-01],
...,
[-1.0288599e+00, -9.5637895e-02, 7.9477325e-02, ...,
-1.8898611e-01, 6.5398413e-01, -1.0675595e+00],
[-1.1164492e-01, 7.7711993e-01, -1.4065570e+00, ...,
3.5607472e-01, 5.6394857e-01, 1.0271224e-01],
[-3.6646339e-01, -7.1605653e-01, 7.9246116e-01, ...,
-6.9521028e-01, 1.4301595e-01, -1.3402353e-01]],
[[ 4.2239037e-01, 4.4505268e-01, -3.8963005e-02, ...,
7.4948013e-01, 8.8290751e-01, -8.9126790e-01],
[-1.3272848e+00, 1.3449454e+00, 6.9998085e-02, ...,
-1.0428437e+00, -2.6193208e-01, 5.1822031e-01],
[-3.3770907e-01, -1.0494056e+00, -1.4558451e+00, ...,
3.8395664e-01, -6.3467842e-01, -7.6225263e-01],
...
nan, nan, nan],
[ nan, nan, nan, ...,
nan, nan, nan],
[ nan, nan, nan, ...,
nan, nan, nan]],
[[ nan, nan, nan, ...,
nan, nan, nan],
[ nan, nan, nan, ...,
nan, nan, nan],
[ nan, nan, nan, ...,
nan, nan, nan],
...,
[ nan, nan, nan, ...,
nan, nan, nan],
[ nan, nan, nan, ...,
nan, nan, nan],
[ nan, nan, nan, ...,
nan, nan, nan]]],
shape=(654, 10, 900), dtype=float32)
Coordinates:
* sample (sample) int64 5kB 0 1 2 3 4 5 6 ... 648 649 650 651 652 653
stim (trial) float64 7kB 1.0 1.0 2.0 2.0 2.0 ... 2.0 2.0 2.0 1.0 2.0
resp (trial) object 7kB 'resp_left' 'resp_right' ... 'resp_right'
RT (trial) float64 7kB 907.0 1.095e+03 1.37e+03 ... 468.0 350.0
cue (trial) object 7kB 'AC' 'AC' 'AC' 'AC' ... 'AC' 'AC' 'SP' 'AC'
movement (trial) object 7kB 'stim_left' 'stim_left' ... 'stim_right'
trigger (trial) object 7kB 'AC/stim_left/resp_left' ... 'AC/stim_rig...
* component (component) int64 80B 0 1 2 3 4 5 6 7 8 9
* trial (trial) object 7kB MultiIndex
* participant (trial) <U16 58kB 'participant3_epo' ... 'participant2_epo'
* epoch (trial) int64 7kB 0 2 3 5 7 8 9 ... 192 193 194 195 197 198 199
Attributes:
sfreq: 300.0
offset: 0Finally, we need to initialize the model.
[5]:
# Defining the expected HMP pattern
event_properties = hmp.patterns.HalfSine.create_expected(sfreq=epoch_data.sfreq)
# Performing the crosscorrelation between the preprocessed data and the expected pattern
trial_data = hmp.trialdata.TrialData.from_transformer(preprocessed, pattern=event_properties.template)
Fitting#
As introduced in Tutorial 2, the CumulativeEstimation method starts by sliding a candidate event from 0 to mean RT. When an event is found – the Expectation Maximization estimation converges – one event is added to the model and the slide continues. This way we can detect new events while accounting for the previous ones.
[6]:
model = hmp.models.CumulativeMethod(event_properties)
_, estimates_cumulative = model.fit_transform(trial_data)
1 events found around times [83]
2 events found around times [86, 280]
3 events found around times [86, 276, 503]
4 events found around times [83, 263, 440, 693]
Found 4 events
[7]:
hmp.visu.plot_topo_timecourse(epoch_data, estimates_cumulative, info, as_time=True)

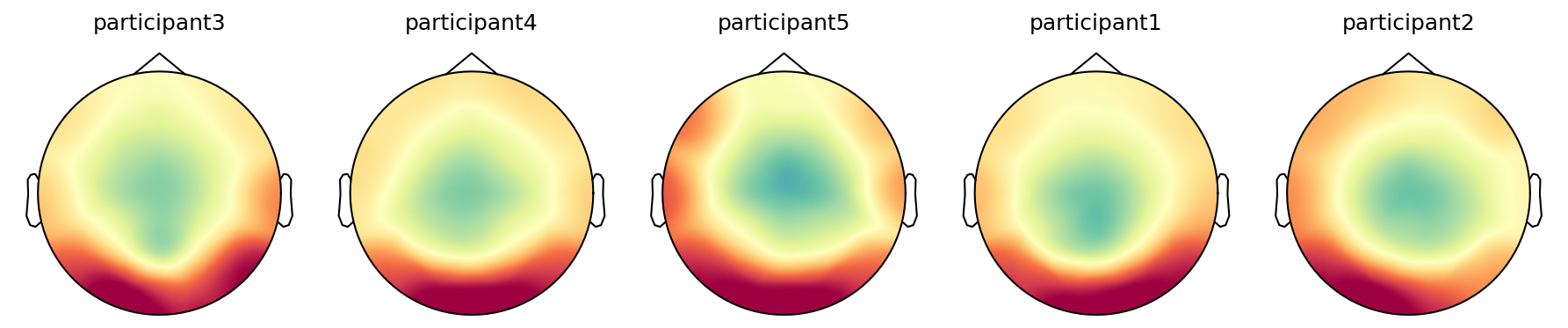
Example application 1: looking at individual topographies#
[8]:
# Plotting individual topographies for a specific event across participants
from mne.viz import plot_topomap
# Get event-channel weights for each trial
by_trial_weights = hmp.utils.event_channels(epoch_data, estimates_cumulative, mean=False)
# Plot topographies for each participant for a selected event
fig, axes = plt.subplots(1, 5, dpi=150, figsize=(12, 2.5))
axes = axes.flatten()
event = 2 # Event index to plot (1-based for display, 0-based for indexing)
# Looking at the topographies of the 5 first participants
for i, participant in enumerate(epoch_data.participant[:5]):
ax = axes[i]
# Average across epochs for the selected event and participant
topo = by_trial_weights.sel(event=event-1, participant=participant).mean('epoch')
plot_topomap(
topo,
info,
sensors=False,
cmap='Spectral_r',
res=100,
show=False,
axes=ax,
contours=False
)
ax.set_title(f'{str(participant.values)[:-4]}')
plt.tight_layout()
Example application 2: analyzing condition effect on interval between events#
[9]:
# Compute max likely time for each trial and each event
times = hmp.utils.event_times(estimates_cumulative, duration=True, add_rt=True, as_time=True)
times
[9]:
<xarray.DataArray (trial: 900, event: 5)> Size: 36kB
array([[ 63.33333333, 160. , 216.66666667, 426.66666667,
36.66666667],
[120. , 226.66666667, 263.33333333, 466.66666667,
13.33333333],
[113.33333333, 176.66666667, 526.66666667, 533.33333333,
16.66666667],
...,
[170. , 170. , 63.33333333, 106.66666667,
16.66666667],
[160. , 80. , 190. , 26.66666667,
6.66666667],
[ 56.66666667, 176.66666667, 70. , 23.33333333,
20. ]], shape=(900, 5))
Coordinates:
* trial (trial) object 7kB MultiIndex
* participant (trial) object 7kB 'participant3_epo' ... 'participant2_epo'
* epoch (trial) int64 7kB 0 2 3 5 7 8 9 ... 192 193 194 195 197 198 199
* event (event) int64 40B 0 1 2 3 4
group (trial) int8 900B 0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0[10]:
# Turn into dataframe and recover metadata
times = times.unstack().to_dataframe(name='duration')
times = times[~times.duration.isna()] #Remove rejected trials
times = times.reset_index().set_index(['participant','epoch'])
# Recover metadata and merge with times
times_metadata = epoch_data.sel(sample=0, channel='Cz').to_dataframe().iloc[:,3:]
times_metadata = times_metadata.reset_index().set_index(['participant','epoch'])
times = times.merge(times_metadata, on=['participant','epoch'])
times
[10]:
| event | group | duration | stim | resp | RT | cue | movement | trigger | ||
|---|---|---|---|---|---|---|---|---|---|---|
| participant | epoch | |||||||||
| participant1_epo | 1 | 0 | 0.0 | 156.666667 | 1.0 | resp_left | 683.0 | SP | stim_left | SP/stim_left/resp_left |
| 2 | 0 | 0.0 | 33.333333 | 1.0 | resp_right | 1068.0 | AC | stim_left | AC/stim_left/resp_right | |
| 3 | 0 | 0.0 | 20.000000 | 1.0 | resp_right | 994.0 | SP | stim_left | SP/stim_left/resp_right | |
| 4 | 0 | 0.0 | 173.333333 | 1.0 | resp_left | 1352.0 | AC | stim_left | AC/stim_left/resp_left | |
| 5 | 0 | 0.0 | 96.666667 | 2.0 | resp_left | 722.0 | SP | stim_right | SP/stim_right/resp_left | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| participant5_epo | 193 | 4 | 0.0 | 16.666667 | 1.0 | resp_right | 555.0 | AC | stim_left | AC/stim_left/resp_right |
| 194 | 4 | 0.0 | 13.333333 | 1.0 | resp_left | 418.0 | AC | stim_left | AC/stim_left/resp_left | |
| 195 | 4 | 0.0 | 16.666667 | 1.0 | resp_right | 377.0 | SP | stim_left | SP/stim_left/resp_right | |
| 197 | 4 | 0.0 | 20.000000 | 1.0 | resp_right | 649.0 | AC | stim_left | AC/stim_left/resp_right | |
| 199 | 4 | 0.0 | 20.000000 | 1.0 | resp_right | 301.0 | AC | stim_left | AC/stim_left/resp_right |
4500 rows × 9 columns
[11]:
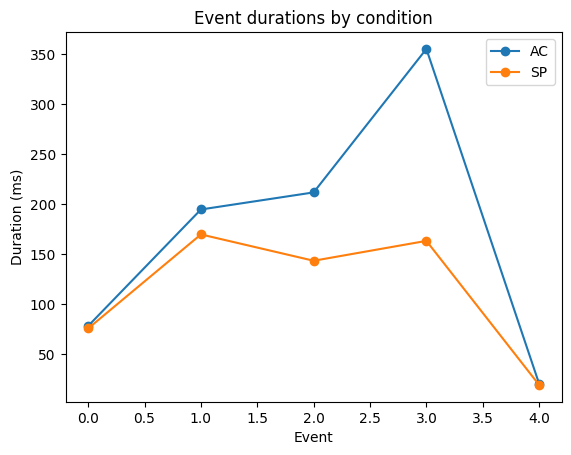
mean_ac = times[times.cue == 'AC'].groupby(['event']).duration.mean()
mean_sp = times[times.cue == 'SP'].groupby(['event']).duration.mean()
plt.plot(mean_ac.index, mean_ac.values, 'o-', label='AC')
plt.plot(mean_sp.index, mean_sp.values, 'o-', label='SP')
plt.legend()
plt.xlabel('Event')
plt.ylabel('Duration (ms)')
plt.title('Event durations by condition')
[11]:
Text(0.5, 1.0, 'Event durations by condition')
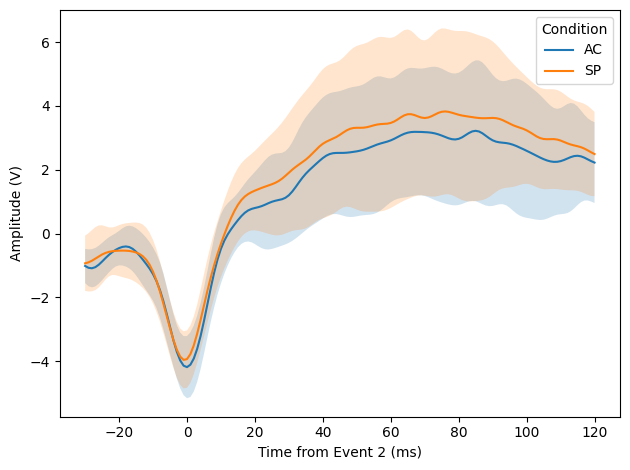
Example application 3: Comparing conditions on centered ERPs:#
[12]:
# Plotting centered ERPs for each condition (AC and SP) with confidence intervals (±1 std)
fig, ax = plt.subplots(1,1)
# Get event times (positions not durations) for all events/trials, including stimulus onset
times_position = hmp.utils.event_times(estimates_cumulative, duration=False, mean=False, add_stim=True)
# Define window size in samples
baseline = -.1*sfreq # 100 ms before event
n_samples = .4*sfreq # 400 ms window
event = 2 # Event index to center on, 0 is stimulus
# Select a subset of channels to analyze (e.g., centroparietal channels)
channel_subset = ['CP1', 'CP2']
for SAT in ["AC","SP"]:
# Select trials for the current condition and stack participant/epoch as 'trial' for easiness
subset = epoch_data.where((epoch_data.cue == SAT), drop=True).stack({'trial':['participant','epoch']}).data.dropna('trial', how="all")
# Center activity on the event for selected channels
centered = hmp.utils.centered_activity(subset, times_position, channel_subset,
event=event, n_samples=n_samples, baseline=baseline)
# Average across channels,
centered = centered.data.unstack().mean('channel')
# Compute mean and std across participants
indiv_traces = centered.groupby('participant').mean(dim='epoch')
mean_tc = indiv_traces.mean('participant')
std_tc = indiv_traces.std('participant')
# Plot the timecourse with confidence interval
ax.plot(centered.sample, mean_tc, label=SAT,)
ax.fill_between(centered.sample, mean_tc-std_tc, mean_tc+std_tc, alpha=0.2)
ax.set_xlabel(f'Time from Event {event} (ms)')
ax.set_ylabel('Amplitude (V)')
plt.legend(title='Condition')
plt.tight_layout()
Splitting conditions#
When estimating a model across all conditions, we can also split the data by condition. This is useful to see how the model estimates differ across conditions, such as speed vs accuracy instructions in this case.
[13]:
speed_epoch_data = epoch_data.where(epoch_data.cue == 'SP').stack({'trial':['participant','epoch']}).dropna('trial', how="all")
accuracy_epoch_data = epoch_data.where(epoch_data.cue == 'AC').stack({'trial':['participant','epoch']}).dropna('trial', how="all")
hmp.visu.plot_topo_timecourse(speed_epoch_data, estimates_cumulative, info, as_time=True, max_time=900)
hmp.visu.plot_topo_timecourse(accuracy_epoch_data, estimates_cumulative, info, as_time=True, max_time=900)


But in this case the HMP parameters are all shared across conditions so we might want to estimate the model separately for each condition if there is a reason to expect a difference. This is done by selecting the condition of interest and then estimating the model on the selected data.
[14]:
speed_preprocessed_data = hmp.utils.condition_selection(preprocessed.data, 'SP', variable='cue')
trial_data_speed = hmp.trialdata.TrialData.from_transformer(speed_preprocessed_data, pattern=event_properties.template)
accuracy_preprocesssed_data = hmp.utils.condition_selection(preprocessed.data, 'AC', variable='cue')
trial_data_accuracy = hmp.trialdata.TrialData.from_transformer(accuracy_preprocesssed_data, pattern=event_properties.template)
[15]:
model_speed = hmp.models.CumulativeMethod(event_properties)
model_speed.fit(trial_data_speed)
ll_cumulative_speed, estimates_speed = model_speed.transform(trial_data_speed)
hmp.visu.plot_topo_timecourse(epoch_data, estimates_speed, info)
1 events found around times [93]
2 events found around times [93, 280]
3 events found around times [90, 276, 536]
Found 3 events

[16]:
model_accuracy = hmp.models.CumulativeMethod(event_properties)
model_accuracy.fit(trial_data_accuracy)
ll_cumulative_accuracy, estimates_accuracy = model_accuracy.transform(trial_data_accuracy)
hmp.visu.plot_topo_timecourse(epoch_data, estimates_accuracy, info)
1 events found around times [83]
2 events found around times [86, 283]
3 events found around times [86, 276, 523]
4 events found around times [86, 273, 503, 826]
Found 4 events

In this case, the models are completely independent and the cumulative method finds an additional event for the accuracy condition, but not for the speed condition.
In the next advanced tutorials we cover how to build models that share some parameters between conditions or participants.